|
지난 첫 번째 글에서는 초개인화의 개념과 중요성, 초개인화 역량체계 및 시스템디자인, 역량체계 구성을 위한 로드맵 등에 대해 고찰해 보았다.
이번 2차 기고에서는 초개인화 역량체계 전반(추천시스템 및 피드백 매커니즘 중심)에 대한 상세한 설명, 핵심 고려사항, 클라우드 인 데이터베이스 애널리틱스(Cloud In-Database Analytics)가 요구되는 이유, 초개인화 시스템 구현을 위한 테라데이터 클라우드 데이터사이언스 솔루션들에 대해 논의하려고 한다.
◆초개인화 고객분석 AI모델체계
초(超) 개인화(Hyper-Personalization)를 위한 역량체계는 ▲고객 360° 뷰 ▲초개인화 고객분석 AI모델 ▲초개인화 아이템 스토어 ▲의사결정 엔진 ▲초개인화 마케팅 실행 및 고객 반응정보 수집 ▲AI모델 고도화를 위한 피드백 매커니즘 이렇게 6가지로 구성된다.
6대 구성요소 중, ▲초개인화 고객분석 AI 모델체계는 4W(To Whom, What, When, Why) 및 1H(How) 5개 모델로 운영된다.
5개 모델은 모두 다른 학습데이터, 모델평가 매트릭스가 요구되며, 잘못된 예측이 고객에게 전달될 경우 발생할 수 있는 비용(Business Cost)의 유형도 모두 상이하다.
상대적으로 난이도가 낮은 ‘투 훔(To Whom)’ 모델의 경우, 머신러닝 모델이 요구되지 않는 경우도 있는데 상품/서비스 변경 발생 시 해당 정보와 관련성이 있는 고객군을 추출하는 것이 그 예이며, 기존의 필터링, 세그먼테이션 등 테크닉으로 커뮤니케이션 대상 고객군 추출이 가능하며 초개인화 영역이라고는 볼 수 없다.
반면, 전략 상품 또는 서비스 홍보 타깃고객 추출을 위해서는 크로스 업셀(Cross/Up Sell) 추천엔진(Recommendation Engine)과 같은 머신러닝 모델을 활용해 해당 오퍼에 대한 수락 확률이 높은 고객 목록을 추출 후, 마케팅 자원을 고려, 최종적인 의사결정을 할 수 있다.
한 가지 고려사항이 있다면, 개별 고객의 유입이 트리거가 되는 경우 ‘투 훔(To Whom)’ 모델은 요구되지 않기에 전체 파이프라인에서 제외된다.
디지털은행 및 보험사, 이커머스, 커뮤니케이션 서비스 등 비즈니스에서는 개별 고객의 유입이 트리거가 되는 경우가 대부분이다.
리테일 비즈니스의 경우에도, 예를 들어 오프라인 매장에 마케팅 대상 고객이 진입한 것을 식별한 경우 ‘투 훔(To Whom)’ 모델이 아닌 ‘추천(What)’ 모델부터 파이프라인은 운영된다.
‘추천(What)’ 모델의 경우, 해외저널 논문, 여러 벤더들의 솔루션에서는 영문표현으로 ‘Next Best Offering(or Action) Model’, ‘Predictive Offer Recommendation Model’, ‘ML Recommender’ 등 여러가지 용어가 사용되고 있다.
추천모델의 가장 큰 역할은, 개별고객이 수락할 확률이 가장 높은 오퍼를 데이터사이언스 및 클라우드 애널리틱스 등 테크닉을 활용하여 실시간으로 추출하는 것에 있다.
이같은 추천모델의 성공(Success)은 ‘개별고객에게 과연 초개인화된 경험을 제공하느냐?’라는 관점으로 측정할 수 있으며, 잘못된 예측은 구글 인사이트(Think With Google) 및 딜로이트(Deloitte) 설문결과(1차 기고)처럼 고객이 오히려 메시지를 차단하거나, 서비스를 탈퇴하는 비용(Cost)을 초래 할 수 있다.
비용 없이, 성공적인 추천모델을 개발하고 비즈니스에 적용하기 위해서는 어떻게 해야 할까? 많은 고려사항이 존재하나, 이번 글에서는 3가지 대표적인 고려사항을 먼저 공유 드리고자 한다.
1. 아이템 스토어(Item Store) 구현 및 실시간 축약(Short-Listed) 아이템 리스트 추출 테크닉 =
만약 개별고객에게 제시 할 아이템(상품, 서비스 또는 정보)의 수가 수천개를 넘지 않으며, 대부분 정형화되어 관리되고 있다면 아이템 스토어(Item Store)를 별도로 구현하거나 실시간으로 축약(Short-Listed) 아이템리스트를 추출할 필요성은 높지 않다.
하지만 디지털 네이티브(Digital Native) 비즈니스의 경우, 아이템 수가 최소 수만개는 넘으며, 계속해서 생성되고 변경될 것이며, 영상/이미지 등 비정형화된 컨텐츠의 비중도 굉장히 높을 것 이다.
별도의 아이템 스토어를 구축하고, 정밀도(Precision) 보다는 재현율(Recall)에 중점을 둔 실시간 축약(Short-Listed) 아이템 추출 테크닉을 개발하고 내재화하는 것이 요구된다.
2. 실시간 추천 아이템 추출을 위한 엔터프라이즈 피처스토어(Enterprise Feature Store) =
‘엔터프라이즈 피처스토어(Enterprise Feature Store)’라는 개념은 특정 머신러닝 프로젝트를 위해 피처 엔지니어링(Feature Engineering) 기법으로 생성된 변수들을 다른 머신러닝 프로젝트를 위해 중앙화해 전사적으로 자산화하자는 아이디어에서 시작됐다.
아래 그림과 같이, 초개인화를 위한 여러 고객분석 유즈케이스에 대해 공통으로 활용될 수 있는 변수들을 사전에 정의하고 재활용성(Reusability)이 높은 변수들은 오프라인 환경에서 피처 엔지니어링 기법을 적용해 생성 후, 피처스토어를 통해 중앙화·자산화해 다른 머신러닝 프로젝트 팀에게 제공하자는 것이다.
이 개념을 초개인화에 적용한다면, 초개인화 고객분석 AI모델의 주요 유의변수(Top Predictors) 들을 오프라인 환경에서 미리 생성하여 피처스토어를 통해 관리하는 체계를 고려해 볼 수 있다.
3~5초 내, 실시간 추천 아이템 추출을 위한 클라우드 피처스토어(Cloud Feature Store)개념이라 할 수 있다.
1차 기고에서 논의된, 이상거래(anomaly detection) 탐지 및 고객알림 초개인화 시나리오를 예로 들면, 하루 한번씩 고객 한명 한명의 ‘최근 3개월 평균 이체 금액’, ‘평균 이체 시간대’, ‘은행 앱 로그인부터 이체까지 걸리는 평균시간’ 등 변수를 오프라인 환경에서 미리 생성해 클라우드 피처스토어에 저장해두는 것이다.
이렇게 되면, 이상거래 탐지모델 파이프라인은 유의변수 생성을 위한 데이터 수집 및 피처 엔지니어링 과정을 생략할 수 있어 사기의심 거래에 대해 고객에게 사전적으로 ‘주의요망’ 메시지를 보내는 것이 기술적으로 가능해진다.
디지털 은행, 보험사, 이커머스, 커뮤니케이션서비스 비즈니스에게 엔터프라이즈 피처스토어(Enterprise Feature Store)는 초개인화를 위한 필수역량으로 자리매김하고 있다.
3. 초개인화 된 경험제공을 위해 가장 어려운 과제는 알고리즘이 아닌 데이터 전처리 =
초개인화 추천모델 개발 과정에서 겪게 되는 가장 어려운 과제는 딥러닝(Deep Learning) 또는 강화학습(Reinforcement Learning) 알고리즘의 튜닝이라고 생각하기 쉽다.
하지만 예상과는 달리 알고리즘 튜닝보다는 희소(Sparse) 데이터, 그 중에서도 밀집(Dense) 데이터 및 범주형(Categorical) 데이터의 전처리가 초개인화 추천모델의 성공적 개발 그리고 성능을 좌우하는 가장 중요한 요인이며 어려운 과제다.
밀집 데이터 및 범주형 데이터가 인공신경망(Neural Network) 등 딥러닝 알고리즘이 필요한 형태로 적절히 전환되지 못하면, 잘못된 초개인화 추천 아이템이 산출될 확률이 높아진다.
예를 들어, 마이데이터 플랫폼의 많은 고객데이터가 이러한 밀집 또는 범주형 형태로 존재하며 고도화된 전처리를 요구할 것이다.
이에, 정규화(Normalization), 임베딩(Embedding) 테이블을 통한 전환, 페어와이즈(Pairwise) 조합 등 데이터 전처리 테크닉을 적절히 적용하는 것이 마이데이터로부터 초개인화 고객인사이트를 추출할 수 있는 가장 중요한 성공요인이라 할 수 있겠다.
‘투 훔(To Whom)’과 ‘추천(What)’ 모델에 대해 논의 해 보았으며, 다음으로 ‘시간대(When)’ 모델, 즉 개별고객 최적 오퍼시간 예측모델은 마케팅 캠페인에 대한 고객반응이력을 학습데이터로 사용할 수 있다.
‘하우(How)’ 모델, 즉 개별고객 최적채널 예측모델 역시 마찬가지다.
고객이 반응했다면 어떤 시간대(평일/주말, 오전/오후/저녁 등)에 반응했는지, 어떤 채널(앱 푸쉬, 이메일, SMS, 아웃바운드 콜, 웹사이트 배너 등)로 오퍼를 확인하거나 수락했는지, 시간대에 따라 채널반응은 달라지는지 등 ‘시간대별 채널별 반응여부’를 타깃데이터로 포함한 학습데이터를 생성할 수 있다.
생성된 학습데이터를 활용해 ‘시간대(When)’과 ‘채널(How)’ 모델을 개발하고 비즈니스에 적용해 ‘추천(What)’ 모델에 의한 초개인화 추천아이템이 고객이 원하는 시간대에 그리고 원하는 채널을 통해 전달되도록 할 수 있다.
최적 오퍼시간 및 채널예측 모델을 비즈니스에 적용하는데 있어 가장 큰 과제는 고객군이 아닌 개별 고객단위로 반응데이터를 수집하게 되면 데이터량 자체가 적어 예측력이 크게 떨어질 수 있다는 것이다.
그 대안으로 고객 프로필 유사도(Similarity)를 활용한 테크닉, 이벤트 기반의 초개인화 오퍼 전달테크닉, 비즈니스 룰(Rule)을 접목한 하이브리드 모델 테크닉 등이 활용되고 있다.
‘시간대(When)’과 ‘채널(How) 모델’과 관련, 고객피로도(Fatigue)에 대한 고려 역시 필요하다.
스스로 동의한 마케팅 캠페인에 대해서도 하루에 너무 많은(최적 시간대에 최적 채널을 통했다 하더라도) 마케팅 캠페인 메시지를 받게되면 추후 마케팅 캠페인에 대한 집중도 하락, 결과적으로 마케팅 캠페인 ROI를 하락시키는 결과를 초래 할 수 있기 때문이다.
이를 별도로 관리하기 위한 고객피로도 모델을 초개인화 고객분석 AI모델체계에 포함할 수 있다.
‘와이(Why) 모델’은 자동화(Automation)에 대한 의사결정 시, 동시에 고려돼야 하는 역량요소이다. AI모델의 추천내용을 활용해 프로세스를 자동화하고자 한다면, 피드백 매커니즘(고객반응 등 실제 결과와 AI모델의 추천내용을 비교, AI모델이 계속해서 최신화 및 고도화 될 수 있도록 하는 역할) 역시 동시에 구현 할 것을 제언드린다.
초개인화 고객 분석 AI모델의 경우, 추천내용에 대한 신뢰도(confidence score)가 상대적으로 낮은 경우 1차적으로 마케팅담당자의 피드백 내용을 학습데이터에 반영 할 수 있다.
2차적으로는 실제 고객반응정보를 활용해 잘못된 예측결과에 대한 피드백을 제공할 수 있으며, 1,2차 피드백을 활용하여 학습데이터를 자동으로 생성할 수 있다.
하지만 고객군 단위가 아닌 개별 고객단위로 추가적인 학습데이터(Labeled Training Data)를 생성하는 것은 상대적으로 더 긴 기간을 요구하며, 학습데이터 확보에 성공했다고 하더라도 초개인화 오퍼나 전달 채널등이 변경될 수 있기에 미래의 개별고객반응을 예측하는데 활용되는 것이 부적절 할 수도 있다.
웹이나 앱과 같은 디지털채널에서 고객이 보이는 여러가지의 반응이나 연속성을 지니는 반응 데이터들을 기계학습 모델이 분석할 수 있는 형태로 전처리하는 것 역시 많은 비용을 요구한다.
게임산업 등을 중심으로 수년전부터 실험을 진행하고 있는 테크닉이 게임 푸쉬 노티스(Push Notice)등을 활용한 강화학습(Reinforcement Learning)기반 피드백 메커니즘의 구현이다.
예를 들어, 게임 푸쉬 노티스(Push Notice)를 특정시간에 보냈을 때 게임유저가 확인했다면 에이전트(이 경우에는 푸쉬 노티스)에게 보상(Reward)를 줘, 에이전트가 스스로 누적 보상(Cumulative Reward)을 최대화하는 방향으로 학습되도록 유도하는 것이다.
이같은 강화학습 기반의 피드백매커니즘이 귀사가 목표로 하는 초개인화 시나리오에 적합할지 빠르게 파악할 수 있는 방법은, 구글, 페이스북, 징가 등에서 내부 실험을 바탕으로 어느 정도 검증된 강화학습 로직을 오픈소스 코드화해 공유한 아래의 자산들을 활용하는 것이다.
• 구글 텐서플로우 에이전트: https://github.com/tensorflow/agents
• 페이스북 리에이전트: https://github.com/facebookresearch/ReAgent
• 징가 강화학습 베이커리(RL Bakery): https://github.com/zynga/rl-bakery
◆클라우드 인 데이터베이스 애널리틱스(Cloud In-Database Analytics) 기반 시스템 구현
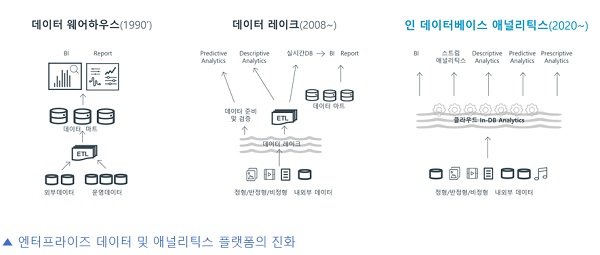
초개인화 시나리오를 실현하기 위해서, 전통적인 데이터아키텍처(데이터웨어하우스 또는 데이터레이크 기반)를 유지하면서 초개인화 AI모델체계를 적용하는 것은 지양해야 한다.
마이데이터 등 고객데이터가 수집되고 관리되는 데이터베이스 내에서 AI모델을 운영해 마케팅시스템에 실시간으로 인사이트(To Whom, What, When, How)를 제공하는 것이 적절한 아키텍처 관점의 지향점이라 할 수 있다.
이같은 개념을 ‘인 데이터베이스 애널리틱스(In-Database Analytics)’라고 정의 할 수 있다.
데이터레이크 환경에서는 전체 데이터 중 일부를 IT의 도움을 받아 ETL등 방법으로 별도 추출 후, 별도의 환경에서 오픈소스 등을 활용 모델 개발 후, 또 다시 IT의 도움을 받아 전체 프로덕션 데이터를 대상으로 개발된 모델을 적용해야만 했다.
이같은 방식으로는 초개인화 AI모델 운영 전, 대부분의 자원과 시간이 데이터 파이프라인에 할애되기에 개별 고객에게 최적화된 오퍼를 제공할 시점이 지난 후에야 AI모델이 분석을 시작하게 될 것이다.
바로 이같은 이유들 때문에 전통적인 방식이 아닌 인 데이터베이스 애널리틱스 기반의 초개인화 시스템 구현이 요구된다 할 수 있다.
즉, 마이데이터, 내외부 정형 및 비정형, 스트리밍 데이터가 수집되는 고객정보 통합 데이터베이스 내에서 ▲별도의 추출이나 개발툴 없이 데이터가 AI모델이 요구하는 형태로 변환되며 ▲초개인화 AI모델에 의해 실시간으로 분석돼 프로덕션 환경에서 예측치를 생성할 수 있어야 하며 ▲레거시(Legacy) 마케팅시스템 및 의사결정 엔진에 실시간으로 인풋을 제공 할 수 있어야 목표 초개인화 시나리오의 실현이 가능하다.
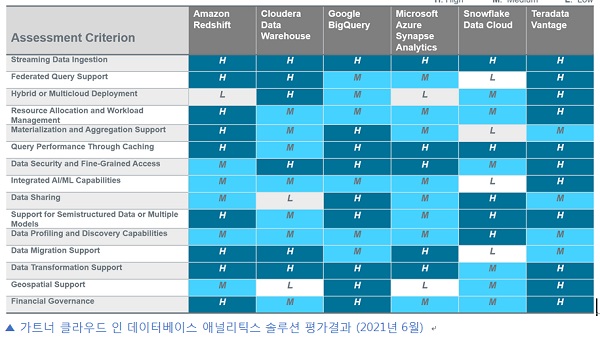
인 데이터베이스 애널리틱스 역량 활용을 위해 고려할 수 있는 벤더, 특히 클라우드 기반의 벤더의 솔루션은 아마존 레드쉬프트(Amazon Redshift), 클라우데라 데이터웨어하우스(Cloudera Data Warehouse), 구글 빅쿼리(Google BigQuery), 마이크로소프트 애저 시냅스(Microsoft Azure Synapse), 스노우플레이크 데이터클라우드(Snowflake Data Cloud), 그리고 테라데이타 벤티지(Teradata Vantage) 등이 대표적이다.
가트너에서 2021년 6월에 공개한 보고서 ‘Solution Comparison for Cloud Data Warehouse Platforms’에 따르면, 모든 평가항목에서 ‘Medium’ 등급 이상의 평가를 받은 솔루션은 구글 빅쿼리와 테라데이터 벤티지 뿐이었으며, 테라데이타 벤티지는 15개 항목 중 11개에서 ‘High’ 등급을 받아 가장 높은 점수를 받았다.
초개인화 AI모델체계와 가장 관련성이 높은 평가항목인 ‘Integrated AI/ML Capabilities’에서는 벤티지만이 유일하게 ‘High’ 등급으로 평가됐다.
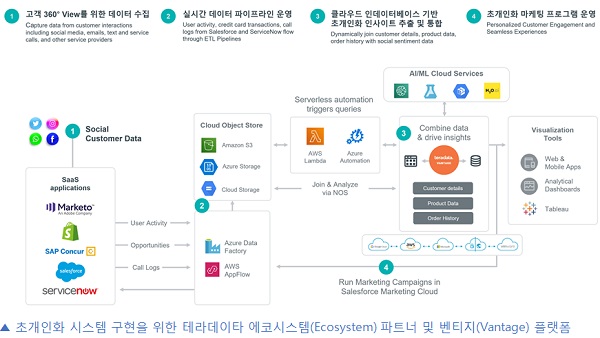
◆인 데이터베이스 애널리틱스 파트너로서의 테라데이타(Teradata)
테라데이타의 인 데이터베이스 애널리틱스 플랫폼 벤티지(Vantage)는 목표 초개인화 시나리오 실현을 위한 클라우드, 데이터, 애널리틱스 파트너와의 에코시스템 상에서 정중앙에 위치한다.
앞서, 추천모델 구현 시 핵심 고려사항으로 논의된 아이템 스토어, 피처 스토어 등을 테라데이타 벤티지를 활용해 구현할 수 있으며, 데이터베이스 내에서 방대한 양의 밀집 및 범주형데이터에 대한 탐색, 정제, 전환, 피처엔지니어링 작업을 진행 할 수 있다.
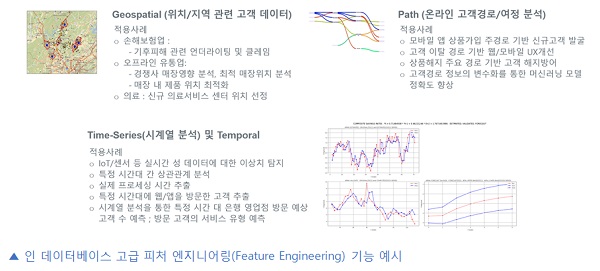
데이터베이스 내에서 제공되는 대표적인 고급 피처엔지니어링 기능으로는 위치/지역 관련 고객데이터 처리를 위한 Geospatial, 온라인 고객행동 데이터(클릭스트림) 처리를 위한 Path, IoT/센서 등 실시간 성 데이터에 대한 이상치 탐지를 위해 활용될 수 있는 데이터 처리를 위한 Time-Series 및 Temporal 등을 들 수 있다.
기타 명목변수 전처리를 위한 One-Hot Encoding, 데이터 정규화를 위한 Scale_Transform, Function_Transform 등 기능, 다항변수 처리를 위한 Polynomial_Features_Transform, 비선형 데이터 처리를 위한 NonLinear_Combine_Transform, 차원축소를 통해 분석가능한 형태로의 전환을 위한 Random Projections 등 기존에는 별도의 솔루션을 통해서만 가능했던 고급 피처 엔지니어링 기능들을 데이터베이서 내에서 활용할 수 있다.
피처 엔지니어링 기능 뿐만이 아니라 XGBoost, Naïve Bayes, ARMA Model 등 머신러닝 알고리즘을 데이터베이스 내에서 SQL기반으로 활용할 수 있다.
덧붙여 파이썬(Python)등 오픈소스 언어 활용을 선호할 경우, 테라데이타 벤티지 내 주피터노트북(Jupyter Notebook)에서 기존의 개발언어를 활용할 수 있다.
기타, 테라데이타 오픈 애널리틱스 프레임워크(Open Analytics Framework, 아래 왼쪽) 그리고 AI 및 BI 파트너 연계(Partner Integration, 아래 오른쪽)를 통해, 목표 초개인화 시나리오 실현을 위해 요구되는 모든 시장의 선두 솔루션들을 인 데이터베이스 애널리틱스(In-Database Analytics) 플랫폼인 테라데이타 벤티지를 통해 활용할 수 있다.
초개인화 추천모델 구현 핵심 고려사항 중 한가지인 엔터프라이즈 피처 스토어(Enterprise Feature Store) 역시 테라데이타 벤티지 플랫폼 내에서 활용가능하며, 마이데이터 등 고객데이터 원천 및 목표 초개인화 시나리오, 목표 시나리오 실현을 위해 요구되는 AI모델 및 유즈케이스(Use Case) 등을 고려, 커스터마이징해 사용할 수 있다.
앞서 소개됐던 고급 피처 엔지니어링 기능들이 모두 포함돼 있어 기업에서는 데이터 원천과 연계, 중앙화해 자산화가 필요한 초개인화 AI모델에 필요한 유의변수(Top Predictor)들을 앞서 소개된 ‘초개인화 고객분석 유즈케이스(Use-Cases)에 공통적으로 사용될 수 있는 변수 예시’ 매트릭스 형태로 분석해 정의하는 작업에 더 포커스 할 수 있다는 장점이 있다.
◆테라데이타 벤티지 플랫폼 및 파트너를 통한 초개인화 파이프라인 자동화(Automation)
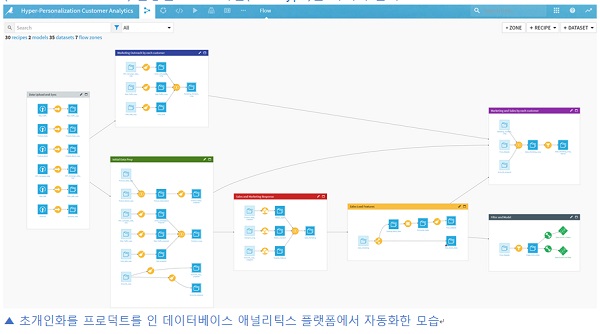
아래 초개인화를 위한 역량체계 구성요소 및 흐름을 다시 살펴보면, 6대 구성요소들은 하나하나가 로드맵의 큰 축을 차지하는 이니셔티브(initiative)임을 알 수 있다.
이해관계자 구조를 고려해 프로덕트 오너(Product Owners)를 지정하고, 각 구성요소 프로덕트 오너(예: 추천모델 프로덕트 오너(PO))들은 인하우스 또는 파트너와 코크리에이션(Co-Creation) 방식을 통해 해당 역량을 개발해 나갈 수 있다.
초개인화 프로덕트(Hyper-Personalization Data & AI Products)가 비즈니스에 적용 가능한 수준으로 개발됐다면, 다음단계는 엔드투엔드(End-To-End) 파이프라인 설계 및 개발이다.
파이프라인 설계 시 중요 고려요소 중 하나는, 휴먼 인 더 루프(Human-in-the-loop) 수준 정의를 통한 파이프라인 자동화(Automation)이다.
초개인화 시나리오 실현을 위해 개발된 엔드투엔드 파이프라인 자동화의 예시로, 테라데이터 벤티지 플랫폼과 파트너 솔루션인 데이터이쿠(Dataiku)의 데이터사시언스 스튜디오(Data Science Studio) 활용한 프로토타입(Prototype)은 아래와 같다.
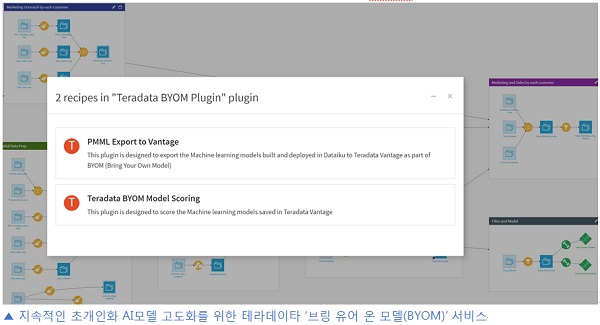
피드백 매커니즘을 통한 추천모델(What), 채널(How), 시간대(When) 최적화 AI모델들의 고도화를 지원하기 위해 ‘브링 유어 온 모델(Bring Your Own Model, BYOM)’라는 서비스를 활용할 수 있으며, IT의 도움을 최소화한 셀프서비스(Self-Service) 머신러닝 옵스(MLOps)체계 구현도 가능하다.
두 차례 기고를 통해 초개인화 역량확보를 위한 비즈니스 고려사항, 데이터 및 AI모델 등 기술적인 고려사항을 살펴보았다.
초개인화 성숙도진단, 로드맵설계, 시나리오정의, 시스템아키텍처 설계 및 인 데이터베이스 애널리틱스 기반 구현 등 테라데이타의 초개인화 엑셀러레이터(Accelerator) 서비스들에 대해 기업경영진들과 더 논의 할 수 있었으면 한다.
<글 = 김인준 테라데이타 AP소속 데이터사이언티스트(상무)>injun.kim@teradata.com < 저작권자 © BI KOREA 무단전재 및 재배포금지 > |